| hive笔记之窗口函数lead()/lag() | 您所在的位置:网站首页 › kale lag › hive笔记之窗口函数lead()/lag() |
hive笔记之窗口函数lead()/lag()
|
一、函数介绍 lag()与lead函数是跟偏移量相关的两个分析函数 通过这两个函数可以在一次查询中取出同一字段的前N行的数据(lag)和后N行的数据(lead)作为独立的列,从而更方便地进行进行数据过滤,该操作可代替表的自联接,且效率更高 lag()/lead() lead(field, num, defaultvalue) field: 需要查找的字段 num: 往后查找的num行的数据 defaultvalue: 没有符合条件的默认值 over() 表示lag()与lead()操作的数据都在over()的范围内,里面可以使用以下子句 partition by 语句(用于分组) order by 语句()用于排序) 如:over(partition by a order by b) 表示以a字段进行分组,再以b字段进行排序,对数据进行查询 二、使用举例 有一个用户购物信息表,里面有name(用户姓名),orderdate(购买日期),cost (消费额)三个字段,表数据如下:  business表数据 business表数据需求:查询顾客上次的购买时间? 思路:先根据name字段进行分组,根据orderdate字段进行组内排序,排完序后使用lag函数取出当前orderdate字段前1行同字段的值,作为新字段值,如果没有设置默认值。 sql如下:  执行结果: 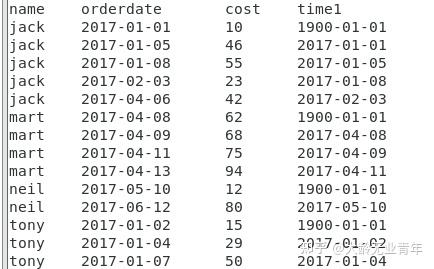
|
【本文地址】
公司简介
联系我们